作者:SHUBHAM JAIN 翻译:和中华 校对:丁楠雅
本文约3500字,建议阅读20分钟。
本文简单介绍了什么是正则化以及在深度学习任务中可以采用哪些正则化技术,并以keras代码具体讲解了一个案例。
简介
数据科学家面临的常见问题之一是如何避免过拟合。你是否碰到过这样一种情况:你的模型在训练集上表现异常好,却无法预测测试数据。或者在一个竞赛中你排在public leaderboard的顶端,但是在最终排名中却落后了几百名?那么这篇文章就是为你而准备的!
(译者注: 在kaggle这样的数据竞赛中, public leaderboard排名是根据一部分测试集来计算的,用于给选手提供及时的反馈和动态展示比赛的进行情况;而private leaderboard是根据测试集的剩余部分计算而来,用于计算选手的最终得分和排名。 通常我们可以把public LB理解为在验证集上的得分,private LB为真正未知数据集上的得分,这样做的目的是提醒参赛者,我们建模的目标是获取一个泛化能力好的模型)
避免过拟合可以提高我们模型的性能。

目录
1. 什么是正则化?
2. 正则化如何减少过拟合?
3. 深度学习中的各种正则化技术:
L2和L1正则化 Dropout 数据增强(Data augmentation) 提前停止(Early stopping)4. 案例:在MNIST数据集上使用Keras的案例研究
1. 什么是正则化?
在深入该主题之前,先来看看这几幅图:

之前见过这幅图吗?从左到右看,我们的模型从训练集的噪音数据中学习了过多的细节,最终导致模型在未知数据上的性能不好。
换句话说,从左向右,模型的复杂度在增加以至于训练误差减少,然而测试误差未必减少。如下图所示:
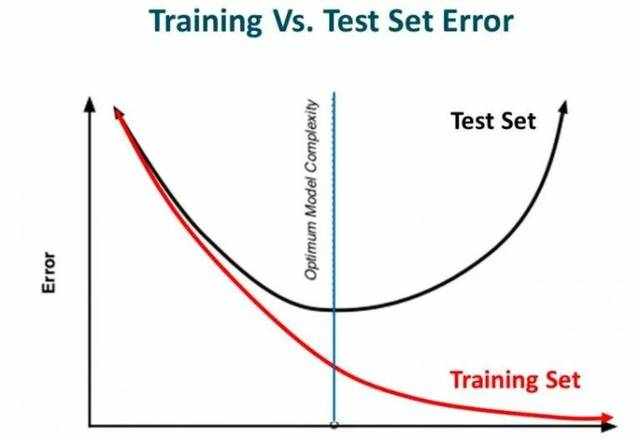
Source: Slideplayer
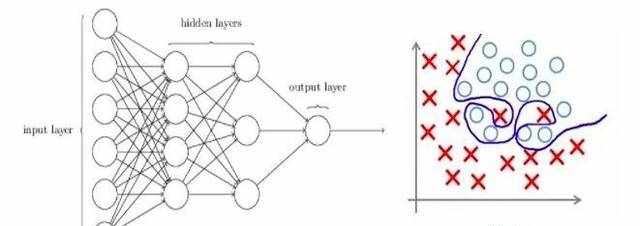
如果你曾经构建过神经网络,你就知道它们有多复杂。这也使得它们更容易过拟合。

正则化技术是对学习算法做轻微的修改使得它泛化能力更强。这反过来就改善了模型在未知数据上的性能。
2. 正则化如何减少过拟合?
我们来看一个在训练数据上过拟合的神经网络,如下图所示:
如果你曾经学习过机器学习中的正则化,你会有一个概念,即正则化惩罚了系数。在深度学习中,它实际上惩罚了节点的权重矩阵。
假设我们的正则化系数很高,以至于某些权重矩阵近乎于0:

这会得到一个简单的线性网络,而且在训练数据集上轻微的欠拟合。
如此大的正则化系数并不是那么有用。我们需要对其进行优化从而得到一个拟合良好的模型,正如下图所示:

3. 深度学习中的各种正则化技术
我们已经理解了正则化如何帮助减少过拟合,现在我们将学习一些把正则化用于深度学习的技术。
L1和L2正则化L1和L2是最常见的正则化类型。它们通过增加一个被称为正则项的额外项来更新成本函数:
Cost function = Loss (say, binary cross entropy) +Regularization term
Cost function = Loss (say, binary cross entropy) +Regularization term
由于增加了这个正则项,权重矩阵的值减小了,因为这里假定了具有较小权重矩阵的神经网络会导致更简单的模型。因此,它也会在相当程度上减少过拟合。
然而,该正则项在L1和L2中是不同的。
L2中,我们有:
这里,lambda是正则参数。它是一个超参数用来优化得到更好的结果。L2正则化也叫权重衰减(weight decay),因为它强制权重朝着0衰减(但不会为0)
在L1中,我们有:
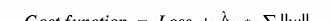
这里,我们惩罚了权重的绝对值。不像L2, 这里的权重是有可能衰减到0的。因此,当我们想压缩模型的时候, L1非常有用,否则会偏向使用L2.
在Keras中,我们可以使用regularizers直接在任意层上应用正则化。
下面是一段样例代码,把L2正则化用于一层之上:
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01)
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01)
注意:这里的值0.01是正则化参数的值,即lambda, 它需要被进一步优化。可以使用grid-search的方法来优化它。
同样的,我们也可以采用L1正则化。后文中的案例研究会看到更多细节。
Dropout这是一种非常有趣的正则化技术。它的效果非常好因此在深度学习领域中最常被使用。
为了理解dropout,假设我们的神经网络结构如下所示:

dropout做什么呢?每次迭代,随机选择一些节点,将它们连同相应的输入和输出一起删掉,如下图:

所以,每一轮迭代都有不同的节点集合,这也导致了不同的输出。它也可以被认为是一种机器学习中的集成技术(ensemble technique)。
集成模型(ensemble models)通常比单一模型表现更好,因为捕获了更多的随机性。同样的,比起正常的神经网络模型,dropout也表现的更好。
选择丢弃多少节点的概率是dropout函数的超参数。如上图所示,dropout可以被用在隐藏层以及输入层。

由于这些原因,当我们有较大的神经网络时,为了引入更多的随机性,通常会优先使用dropout。
在Keras中,可以使用Keras core layer来实现dropout。下面是对应的Python代码:
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
正如你看到的,这里定义丢弃概率为0.25。我们可以使用grid search方法来微调它以获得更好的结果。
数据增强(Data augmentation)减少过拟合最简单的方式其实是增加训练集的大小。在机器学习中,由于人工标注数据成本过高所以很难增加训练集的大小。
但是,考虑一下如果我们处理的是图像。在这种情况下,有一些方法可以增加训练集的大小——旋转、翻转、缩放、移动等等。下图中,对手写数字数据集进行了一些转换:

这种技术叫做数据增强。通常会明显改善模型的准确率。为了提高模型预测能力,这种技术可以被视为一种强制性技巧。
在Keras中,我们使用ImageDataGenerator来执行所有这些转换。它有一大堆参数,你可以用它们来预处理你的训练数据。
下面是示例代码:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal flip=True)
datagen.fit(train)
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal flip=True)
datagen.fit(train)
提前停止(Early stopping)提前停止是一种交叉验证的策略,即把一部分训练集保留作为验证集。当看到验证集上的性能变差时,就立即停止模型的训练。
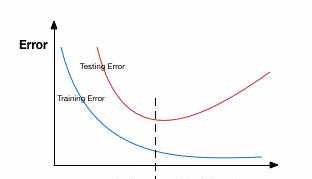
在上图中,我们在虚线处停止模型的训练,因为在此处之后模型会开始在训练数据上过拟合。
在Keras中,使用callbacks函数来应用提前停止。下面是代码:
from keras.callbacks import EarlyStopping
EarlyStopping(monitor='val_err', patience=5)
from keras.callbacks import EarlyStopping
EarlyStopping(monitor='val_err', patience=5)
这里的monitor是表示需要监视的量,‘val_err’代表验证集错误.
Patience表示在该数量的epochs内没有进一步的性能改进后,就停止训练。为了更好地理解,我们再看看上面的图。在虚线之后,每个epoch都会导致一个更高的验证集错误。因此,在虚线之后的5个epoch(因为我们设置patience等于5),由于没有进一步的改善,模型将停止训练。
注意:可能在5个epoch之后(这是一般情况下为patience设定的值)模型再次开始改进,并且验证集错误也开始减少。因此,在调整这个超参数的时候要格外小心。
在MNIST数据集上使用Keras的案例研究至此,你应该对我们提到的各种技术有了一个理论上的理解。现在我们把这些知识用在深度学习实际问题上——识别数字。下载完数据集之后,你就可以开始下面的代码。首先,我们导入一些基本的库。
%pylab inline
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
import tensorflow as tf
import keras
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)
%pylab inline
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
import tensorflow as tf
import keras
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)
现在,加载数据。
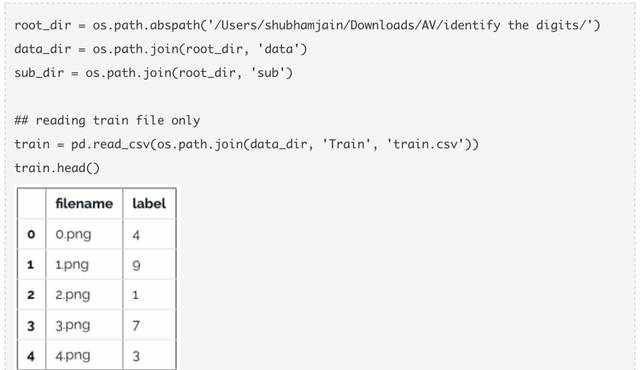
现在拿一些图片来看看。
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()
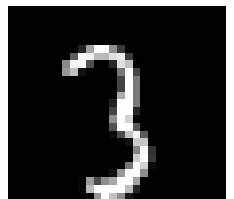
#storing images in numpy arrays
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
x_train = np.stack(temp)
x_train /= 255.0
x_train = x_train.reshape(-1, 784).astype('float32')
y_train = keras.utils.np_utils.to_categorical(train.label.values)
#storing images in numpy arrays
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
x_train = np.stack(temp)
x_train /= 255.0
x_train = x_train.reshape(-1, 784).astype('float32')
y_train = keras.utils.np_utils.to_categorical(train.label.values)
创建一个验证集,以便优化我们的模型以获得更好的分数。我们将采用70:30的训练集、验证集比例。
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = x_train[:split_size], x_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = x_train[:split_size], x_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
首先,我们先建立一个具有5个隐藏层,每层500个节点的简单神经网络。
# import keras modules
from keras.models import Sequential
from keras.layers import Dense
# define vars
input_num_units = 784
hidden1_num_units = 500
hidden2_num_units = 500
hidden3_num_units = 500
hidden4_num_units = 500
hidden5_num_units = 500
output_num_units = 10
epochs = 10
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
# import keras modules
from keras.models import Sequential
from keras.layers import Dense
# define vars
input_num_units = 784
hidden1_num_units = 500
hidden2_num_units = 500
hidden3_num_units = 500
hidden4_num_units = 500
hidden5_num_units = 500
output_num_units = 10
epochs = 10
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
注意,我们只运行10个epoch,快速检查一下模型的性能。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

现在,我们尝试用L2正则化,并检查它是否给出了比简单神经网络更好的性能。
from keras import regularizers
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
from keras import regularizers
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

注意这里lambda的值等于0.0001. 太棒了!我们获得了一个比之前NN模型更好的准确率。
现在尝试一下L1正则化。
## l1
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
## l1
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

这次并没有显示出任何的改善。我们再来试试dropout技术。
## dropout
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
## dropout
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

效果不错!dropout也在简单NN模型上给出了一些改善。
现在,我们试试数据增强。
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(zca_whitening=True)
# loading data
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
x_train = np.stack(temp)
X_train = x_train.reshape(x_train.shape[0], 1, 28, 28)
X_train = X_train.astype('float32')
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(zca_whitening=True)
# loading data
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
x_train = np.stack(temp)
X_train = x_train.reshape(x_train.shape[0], 1, 28, 28)
X_train = X_train.astype('float32')
现在,拟合训练数据以便增强。
# fit parameters from data
datagen.fit(X_train)
# fit parameters from data
datagen.fit(X_train)
这里,我使用了zca_whitening作为实参,它突出了每个数字的轮廓,如下图所示:

## splitting
y_train = keras.utils.np_utils.to_categorical(train.label.values)
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = X_train[:split_size], X_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
## reshaping
x_train=np.reshape(x_train,(x_train.shape[0],-1))/255
x_test=np.reshape(x_test,(x_test.shape[0],-1))/255
## structure using dropout
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
## splitting
y_train = keras.utils.np_utils.to_categorical(train.label.values)
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = X_train[:split_size], X_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
## reshaping
x_train=np.reshape(x_train,(x_train.shape[0],-1))/255
x_test=np.reshape(x_test,(x_test.shape[0],-1))/255
## structure using dropout
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

哇!我们在准确率得分上有了一个飞跃。并且好消息是它每次都奏效。我们只需要根据数据集中的图像来选择一个合适的实参。
现在,试一下最后一种技术——提前停止。
from keras.callbacks import EarlyStopping
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test)
, callbacks = [EarlyStopping(monitor='val_acc', patience=2)])
from keras.callbacks import EarlyStopping
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test)
, callbacks = [EarlyStopping(monitor='val_acc', patience=2)])

可以看到我们的模型在仅仅5轮迭代后就停止了,因为验证集准确率不再提高了。当我们使用更大值的epochs来运行它时,它会给出好的结果。你可以说它是一种优化epoch值的技术。
结语
我希望现在你已经理解了正则化以及在深度学习模型中实现正则化的不同技术。无论你处理任何深度学习任务,我都强烈建议你使用正则化。它将帮助你开阔视野并更好的理解这个主题。
原文链接:
https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/
原文链接:
https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/
译者简介:和中华,留德软件工程硕士。由于对机器学习感兴趣,硕士论文选择了利用遗传算法思想改进传统kmeans。目前在杭州进行大数据相关实践。加入数据派THU希望为IT同行们尽自己一份绵薄之力,也希望结交许多志趣相投的小伙伴。
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
1.《深度学习中的正则化技术(附Python代码)》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《深度学习中的正则化技术(附Python代码)》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/tiyu/23810.html